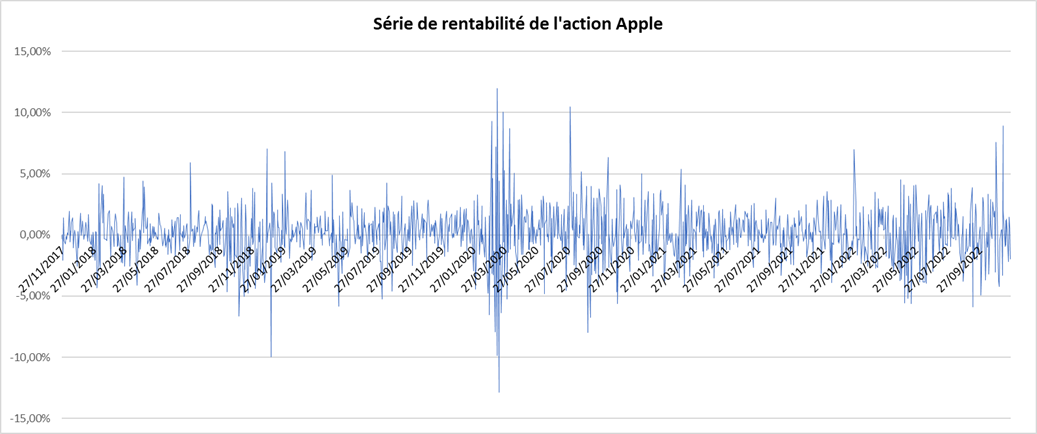
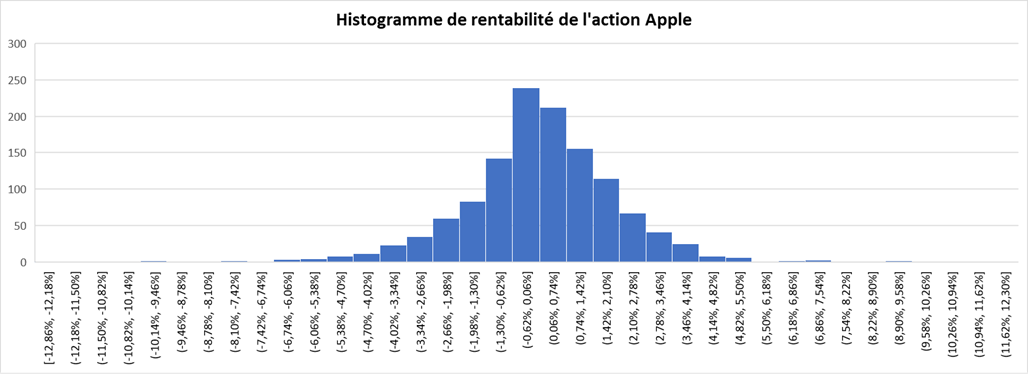
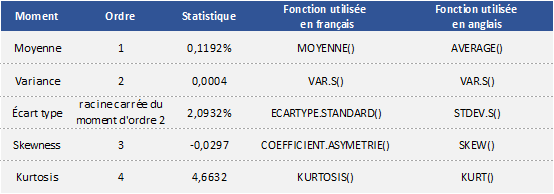
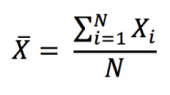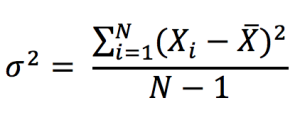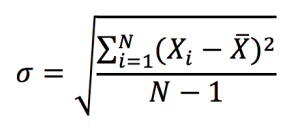Dans cet article, Shengyu ZHENG (ESSEC Business School, Grande Ecole Program – Master in Management, 2020-2023) présente les mesures de risques basées sur la distribution statistique des rentabilités d’une position de marché, ce qui est une approche possible pour mesurer les risques (comme expliqué dans mon article Catégorie de mesures de risques).
Les mesures de risques basées sur la distribution statistique sont des outils largement utilisés pour la gestion des risques par de nombreux de participants du marché, dont les traders, les teneurs de marché, les gestionnaires d’actifs, les assureurs, les institutions réglementaires et les investisseurs.
Ecart-type / Variance
La variance (moment d’ordre deux de la distribution statistique) est une mesure de la dispersion des valeurs par rapport à la moyenne. La variance est définie par
Var(X) = σ 2 = 𝔼[(X-μ)2]
Par construction, la variance est toujours positive (ou nulle pour une variable aléatoire constante).
En finance, l’écart-type (racine carrée de la variance) mesure la volatilité des actifs financiers. Un écart-type (ou une variance élevée) indique une dispersion plus importante, et donc un risque plus important, ce n’est pas apprécié par les investisseurs qui ont de l’aversion au risque. L’écart-type (ou la variance) est un paramètre clef dans la théorie moderne du portefeuille de Markowitz.
La variance a un estimateur non biaisé donné par
Ŝ2 = (∑ni=1(xi – X̄)2)/(n-1)
Value at Risque (VaR)
La Value at Risque (VaR, parfois traduite comme valeur en enjeu) est une notion classique pour mesurer les risques de perte d’un actif. Elle correspond au montant de perte d’une position qui ne devrait être dépassé qu’avec une probabilité donnée sur un horizon précisé, ou autrement dit, au montant de la pire perte attendue sur un horizon de temps pour un certain niveau de confiance. Elle est essentiellement le quantile de la probabilité donnée de la distribution de perte (rendement négatif).
Dans le langage mathématique, la VaR est définie comme :
VaRα = inf{y ∈ : ℙ[L>y] ≤ 1 – α} = inf{ y ∈ : ℙ[L ≤ y] ≥ α }
VaRα = qα(F) ≔ F←(α)
α est la probabilité donnée ; L est une variable aléatoire de montant de perte ; F est la distribution cumulative de perte (rendement négatif), ce qui est continue et strictement croissante ; F← est l’inverse de F.
Les organismes financiers se servent assez souvent de cette mesure pour la rapidité et la simplicité des calculs. Toutefois, elle présente certaines lacunes. Elle n’est pas une mesure cohérente. Cela dit, l’addition des VaRs de 2 portefeuilles aurait aucun sens. À part cela, basée sur une hypothèse gaussienne, elle ne tient pas compte de la gravité et la possibilité des évènements extrêmes, tant que les distributions du marché financier sont, pour la plupart, leptokurtiques.
Expected Shortfall (ES)
L’Expected shortfall (ES) est la perte espérée pendant N jours conditionnellement au fait de se situer dans la queue (1 – α) de la distribution des gains ou des pertes (N est l’horizon temporel et α est le niveau de confiance). Autrement dit, elle est la moyenne des pertes lors d’un choc qui est pire que α% cas. L’ES est donc toujours supérieure à la VaR. Elle est souvent appelée VaR conditionnelle (CVaR).
ESα = ∫ 1α (VaRβ(L) dβ)/(1 – α)
En comparaison de la VaR, ES est capable de montrer la gravité de perte dans des cas extrêmes. Ce point est primordial pour la gestion moderne de risques qui souligne la résilience surtout en cas d’extrême.
La VaR a été préférée par les participants du marché financier depuis longtemps, mais les défauts importants présentés ci-dessus ont occasionné des reproches, notamment face aux souvenances des crises majeures. L’ES, rendant compte des évènements extrêmes, tend désormais à s’imposer.
Stress Value (SV)
La Stress Value (SV) est un concept similaire à la VaR. Comme la VaR, la SV est définie comme un quantile. Pour la SV, la probabilité associée au quantile est proche de 1 (par exemple, un quantile de 99.5% pour la SV, en comparaison d’un quantile de 95% pour la VaR habituelle). La SV décrit plus précisément les pertes extrêmes.
L’estimation paramétrique de SV normalement s’appuie sur la théorie de valeurs extrêmes (EVT), alors que celle de VaR est basée sur une distribution gaussienne.
Programme R pour calculer les mesures de risques
Vous pouvez télécharger ci-dessous un programme R qui permet de calculer les mesures de risques d’une position de marché (construite à partir d’indices d’actions ou d’autres actifs).

Voici est une liste des symboles d’actif (“tickers”) que nous pouvons intégrer dans le programme R.

Example de calcul des mesures de risque de l’indice S&P 500
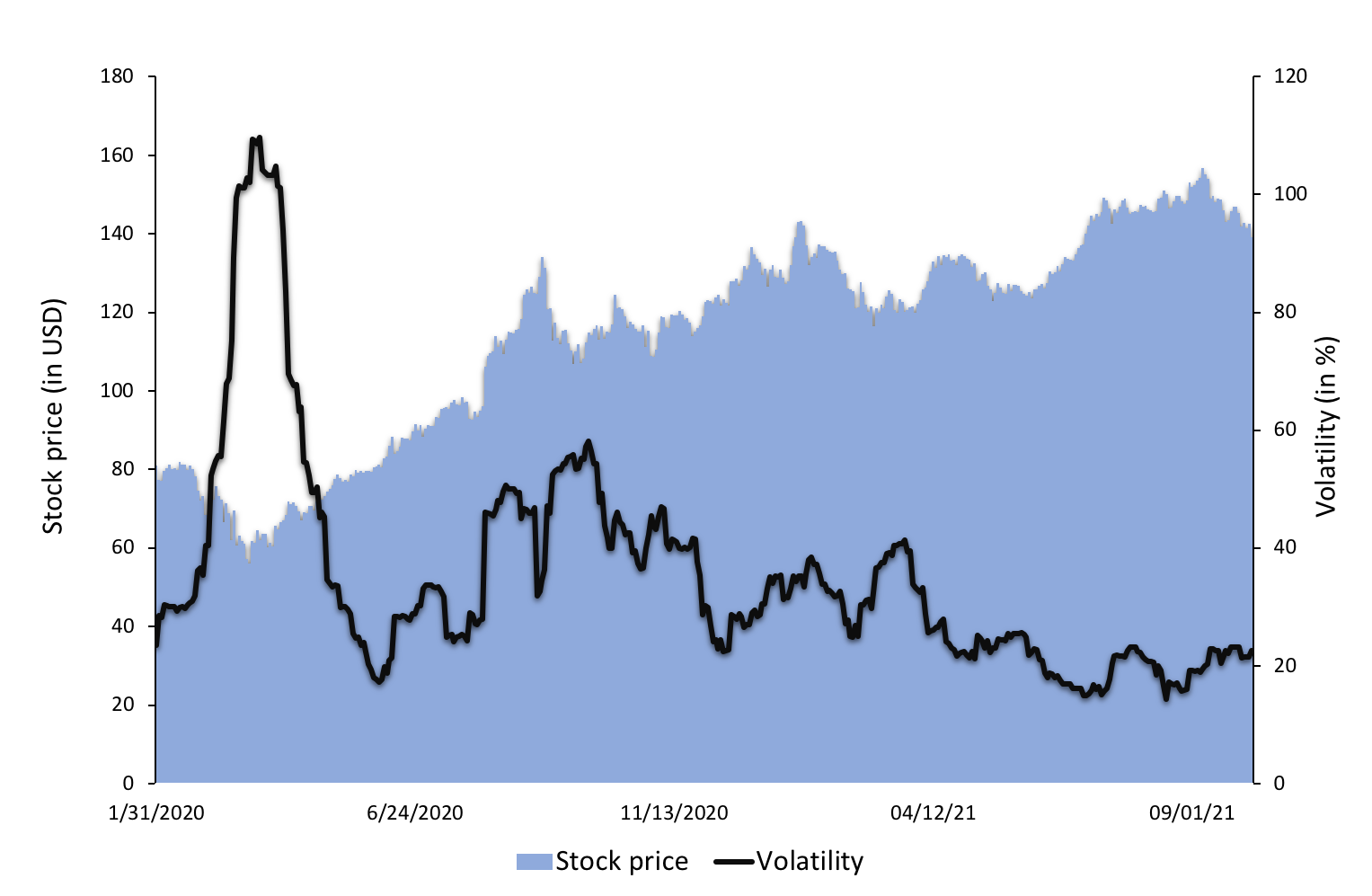
Ce programme nous permet de calculer rapidement des mesures de risque pour des actifs financiers dont les données historiques peuvent être téléchargées sur le site Yahoo! Finance. Je vous présente une analyse de risque pour l’indice S&P 500.
En saisissant la date de début comme 01/01/2012 et la date d’arrêté comme 01/01/2022, ce programme est en mesure de calculer les mesures de risque pour toute la période considérée.
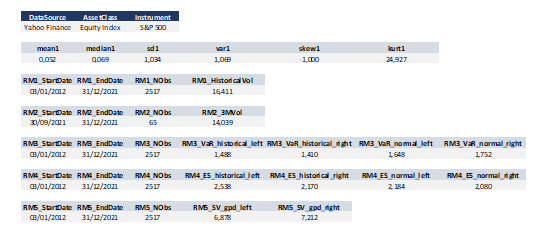
Vous trouverez ci-dessous les mesures de risque calculées pour toute la période : la volatilité historique, la volatilité conditionnelle sur les 3 derniers mois, VaR, ES et SV.
Autres articles sur le blog SimTrade
▶ Shengyu ZHENG Catégories de mesures de risques
▶ Shengyu ZHENG Moments de la distribution
▶ Shengyu ZHENG Extreme Value Theory: the Block-Maxima approach and the Peak-Over-Threshold approach
▶ Youssef LOURAOUI Markowitz Modern Portfolio Theory
Ressources
Articles académiques
Merton R.C. (1980) On estimating the expected return on the market: An exploratory investigation, Journal of Financial Economics, 8:4, 323-361.
Hull J. (2010) Gestion des risques et institutions financières, Pearson, Glossaire français-anglais.
Données
A propos de l’auteur
Cet article a été écrit en février 2023 par Shengyu ZHENG (ESSEC Business School, Grande Ecole Program – Master in Management, 2020-2023).