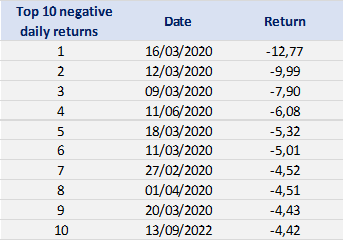
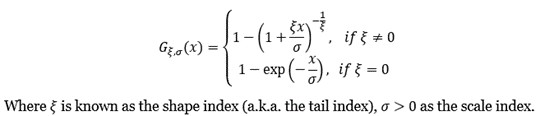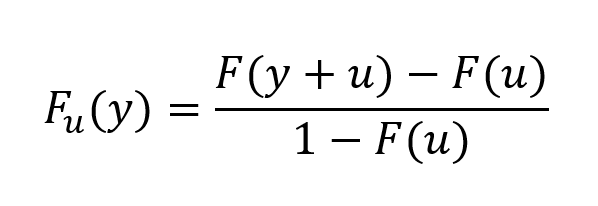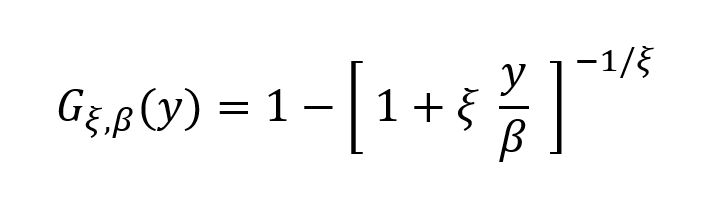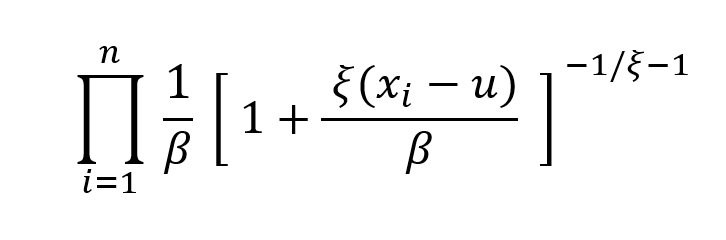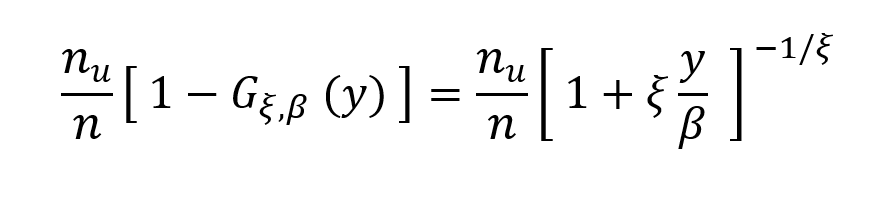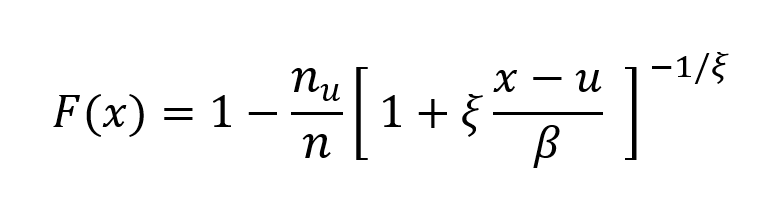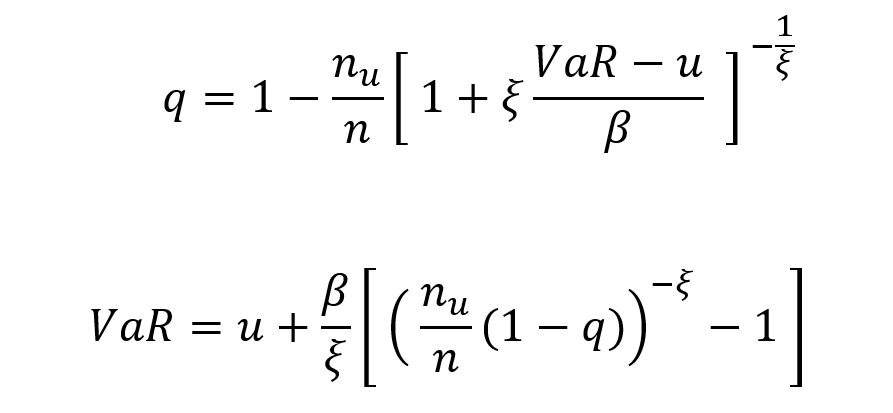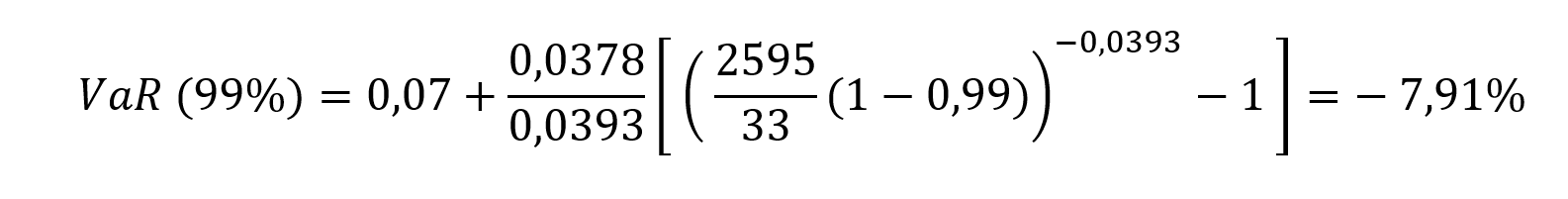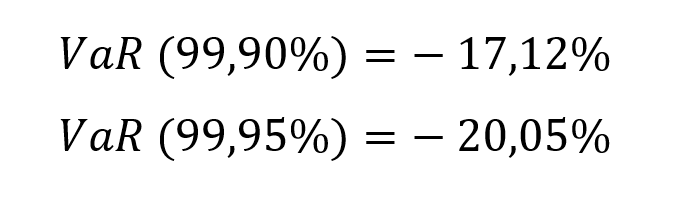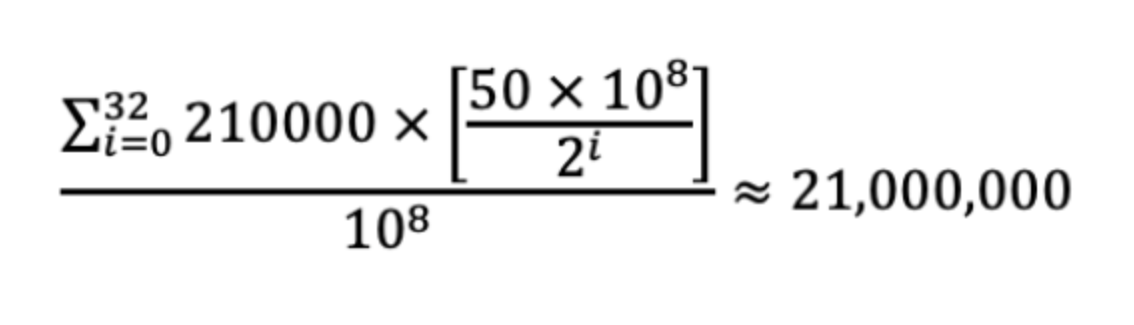In this article, Snehasish CHINARA (ESSEC Business School, Grande Ecole Program – Master in Management, 2022-2024) explains Bitcoin which is considered as the mother of all cryptocurrencies.
Historical context and background
The genesis of Bitcoin can be traced back to the aftermath of the Financial Crisis of 2008, when a growing desire emerged for a currency immune to central authority control. Traditional banks had faltered, leading to the devaluation of money through government-sanctioned printing. The absence of a definitive limit on money creation fostered uncertainty. Bitcoin ingeniously addressed this quandary by establishing a fixed supply of coins and a controlled production rate through transparent coding. This code’s openness ensured that no entity, including governments, could manipulate the currency’s value. Consequently, Bitcoin’s worth became solely determined by market dynamics, evading the arbitrary alterations typical of government-managed currencies.
Furthermore, Bitcoin revolutionized financial transactions by eliminating reliance on third-party intermediaries, exemplified by banks. Users can now engage in direct peer-to-peer transactions, circumventing the potential for intermediaries to engage in risky financial ventures akin to the 2008 Financial Crisis. The process of safeguarding one’s Bitcoins is equally innovative, as users manage their funds through a Bitcoin Wallet. Unlike traditional banks, these wallets operate as personal assets, with users as their own bankers. While various companies offer wallet services, the underlying code remains accessible for review, ensuring customers’ trust and the safety of their deposits.
Bitcoin Logo
![]()
Source: internet.
Figure 1. Key Dates in Bitcoin History
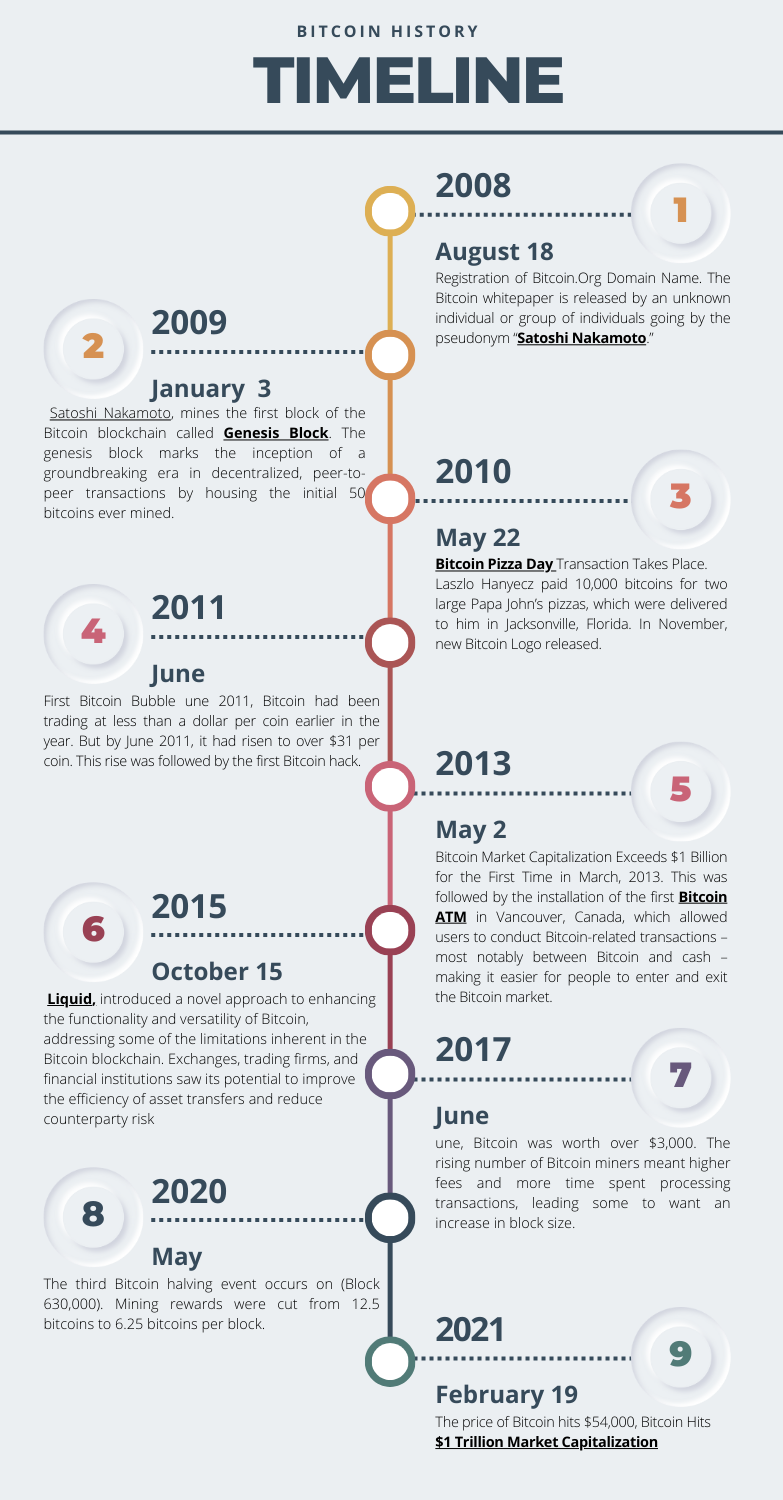
Source: author of this post.
Key features and use cases
Examples of areas where Bitcoin is currently being used:
- Digital Currency: Bitcoin serves as a digital currency for everyday transactions, allowing users to buy goods and services online and in physical stores.
- Crypto Banking: Bitcoin is used in decentralized finance (DeFi) applications, where users can lend, borrow, and earn interest on their Bitcoin holdings.
- Asset Tokenization: Bitcoin is used to tokenize real-world assets like real estate and art, making them more accessible and divisible among investors.
- Onchain Governance: Some blockchain projects utilize Bitcoin for on-chain governance, enabling token holders to vote on protocol upgrades and changes.
- Smart Contracts: While Ethereum is more widely associated with smart contracts, Bitcoin’s second layer solutions like RSK (Rootstock) allow for the execution of smart contracts on the Bitcoin blockchain.
- Corporate Treasuries: Large corporations, such as Tesla, have invested in Bitcoin as a store of value and an asset to diversify their corporate treasuries.
- State Treasuries: Some countries, like El Salvador, have adopted Bitcoin as legal tender and added it to their national treasuries to facilitate cross-border remittances and financial inclusion.
- Store of Value During Times of Conflict: In regions with economic instability or conflict, Bitcoin is used as a hedge against currency devaluation and asset confiscation.
- Online Gambling: Bitcoin is widely accepted in online gambling platforms, providing users with a secure and pseudonymous way to wager on games and sports.
- Salary Payments for Freelancers in Emerging Markets: Freelancers in countries with limited access to traditional banking use Bitcoin to receive payments from international clients, circumventing costly and slow remittance services.
- Cross-Border Transactions with Bitcoin Gold: Cross-border transactions can often be complex, time-consuming, and costly due to the involvement of multiple intermediaries and the varying regulations of different countries. However, Bitcoin Gold offers a streamlined solution for facilitating global payments, making cross-border transactions more efficient and accessible.
These examples highlight the diverse utility of Bitcoin, ranging from everyday transactions to more complex financial applications and as a tool for economic empowerment in various contexts.
Technology and underlying blockchain
Blockchain technology is the foundational innovation that underpins Bitcoin, the world’s first and most well-known cryptocurrency. At its core, blockchain is a decentralized and distributed ledger system that records transactions across a network of computers in a secure and transparent manner. In the context of Bitcoin, this blockchain serves as a public ledger that tracks every transaction ever made with the cryptocurrency. What sets blockchain apart is its ability to ensure trust and security without the need for a central authority, such as a bank or government. Each block in the chain contains a set of transactions, and these blocks are linked together in a chronological and immutable fashion. This means that once a transaction is recorded on the blockchain, it cannot be altered or deleted. This transparency, immutability, and decentralization make blockchain technology a revolutionary tool not only for digital currencies like Bitcoin but also for a wide range of applications in various industries, from finance and supply chain management to healthcare and beyond.
Moreover, Bitcoin operates on a decentralized network of computers (nodes) worldwide. These nodes validate and confirm transactions, ensuring that the network remains secure, censorship-resistant, and immune to central control. The absence of a central authority is a fundamental characteristic of Bitcoin and a key differentiator from traditional financial systems. Bitcoin relies on a PoW consensus mechanism for securing its network. Miners compete to solve complex mathematical puzzles, and the first one to solve it gets the right to add a new block of transactions to the blockchain. This process ensures the security of the network, prevents double-spending, and maintains the integrity of the ledger. Bitcoin has a fixed supply of 21 million coins, a feature hard-coded into its protocol. The rate at which new Bitcoins are created is reduced by half approximately every four years through a process known as a “halving.” This limited supply is in stark contrast to fiat currencies, which can be printed without restriction.
These technological aspects collectively make Bitcoin a groundbreaking innovation that has disrupted traditional finance and is increasingly studied and integrated into the field of finance. It offers unique opportunities and challenges for finance students to explore, including its impact on monetary policy, investment, and the broader financial ecosystem.
Supply of coins
Looking at the supply side of bitcoins, the number of bitcoins in circulation is given by the following mathematical formula:
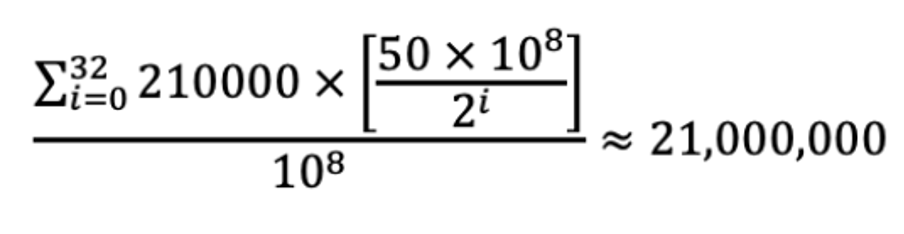
This calculation hinges upon the fundamental concept of the Bitcoin supply schedule, which employs a diminishing issuance rate through a process known as “halving”.
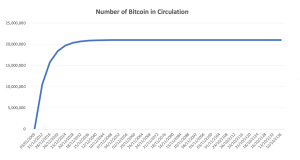
Figure 2 represents the evolution of the number of bitcoins in circulation overt time based on the above formula.
Figure 2. Number of bitcoins in circulation
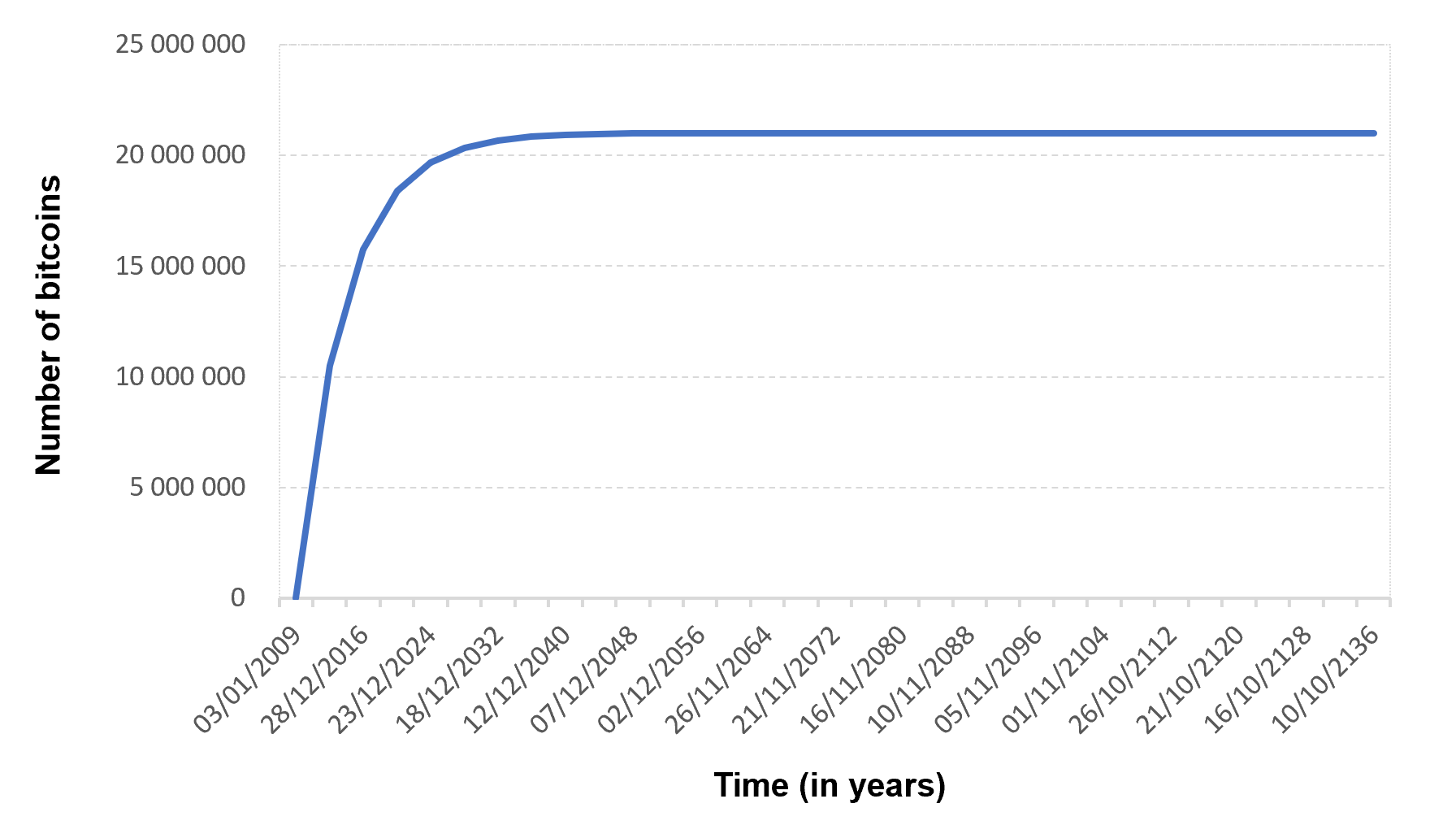
Source: computation by the author.
You can download below the Excel file for the data and the figure of the number of bitcoins in circulation.

Historical data for Bitcoin
How to get the data?
The Bitcoin is the most popular cryptocurrency on the market, and historical data for the Bitcoin such as prices and volume traded can be easily downloaded from the internet sources such as Yahoo! Finance, Blockchain.com & CoinMarketCap. For example, you can download data for Bitcoin on Yahoo! Finance (the Yahoo! code for Bitcoin is BTC-USD).
Figure 4. Bitcoin data
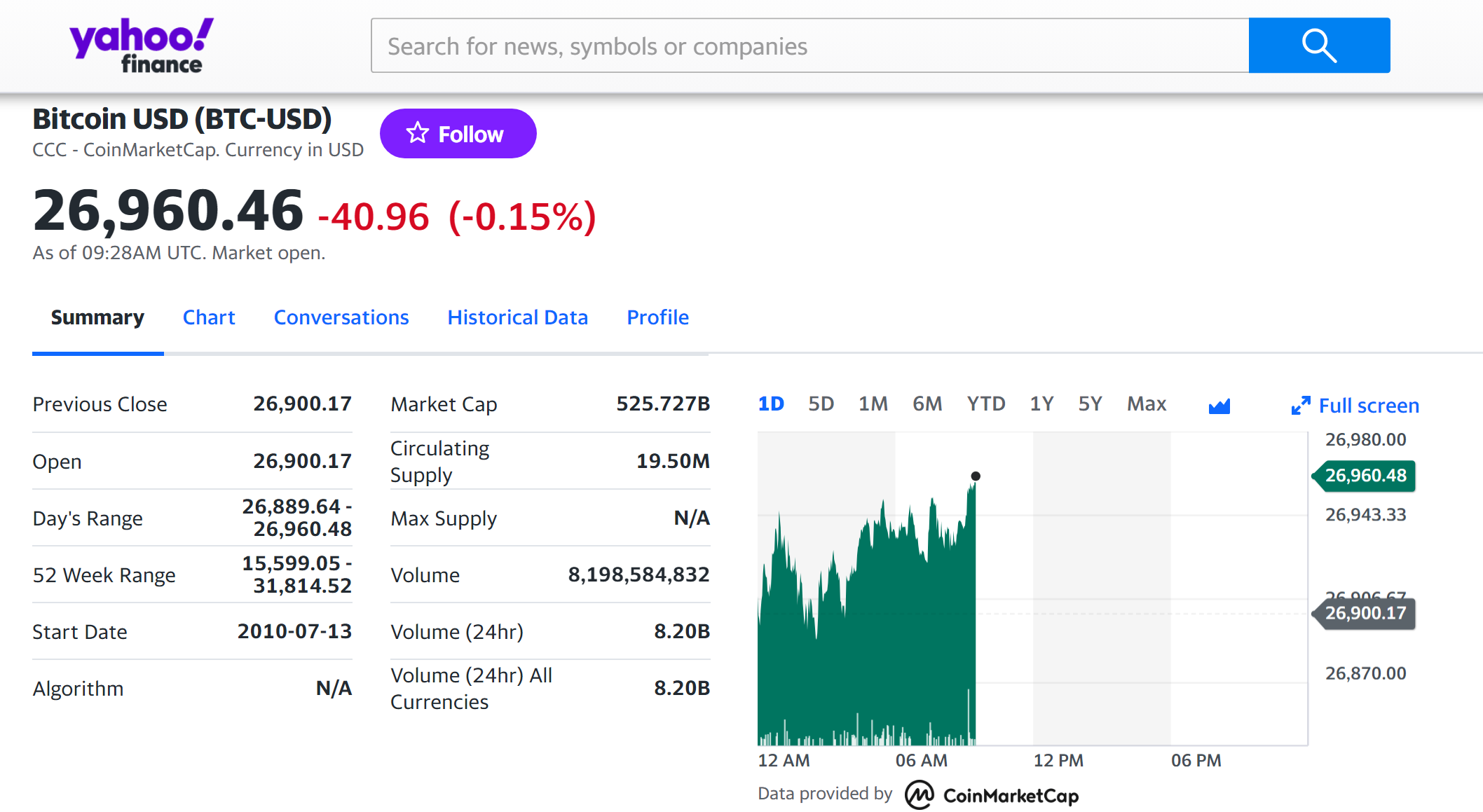
Source: Yahoo! Finance.
Historical data for the Bitcoin market prices
The market price of Bitcoin is a dynamic and intricate element that reflects a multitude of factors, both intrinsic and extrinsic. The gradual rise in market value over time indicates a willingness among investors and traders to offer higher prices for the cryptocurrency. This signifies a rising interest and strong belief in the project’s potential for the future. The market price reflects the collective sentiment of investors and traders. Comparing the market price of Bitcoin to other similar cryptocurrencies or benchmark assets can provide insights into its relative strength and performance within the market.
The value of Bitcoin in the market is influenced by a variety of elements, with each factor contributing uniquely to their pricing. One of the most significant influences is market sentiment and investor psychology. These factors can cause prices to shift based on positive news, regulatory changes, or reactive selling due to fear. Furthermore, the real-world implementations and usages of Bitcoin are crucial for its prosperity. Concrete use cases such as Decentralized Finance (DeFi), Non-Fungible Tokens (NFTs), and international transactions play a vital role in creating demand and propelling price appreciation. Meanwhile, adherence to basic economic principles is evident in the supply-demand dynamics, where scarcity due to limited issuance, halving events, and token burns interact with the balance between supply and demand.
With the number of coins in circulation, the information on the price of coins for a given currency is also important to compute Bitcoin’s market capitalization.
Figure 5 below represents the evolution of the price of Bitcoin in US dollar over the period October 2014 – August 2023. The price corresponds to the “closing” price (observed at 10:00 PM CET at the end of the month).
Figure 5. Evolution of the Bitcoin price
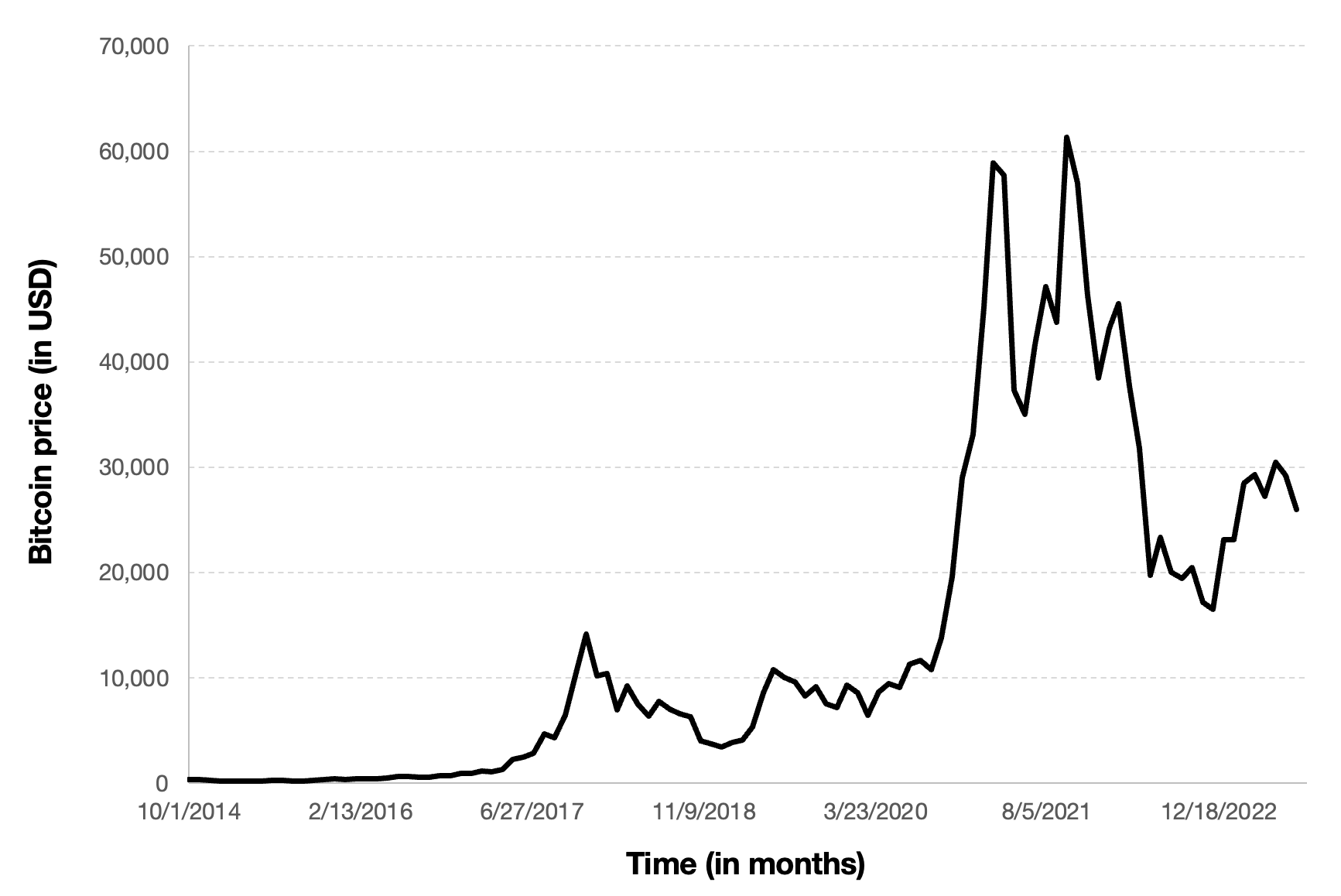
Source: computation by the author (data source: Yahoo! Finance).
Python code
Python script to download Bitcoin historical data and save it to an Excel sheet::
import yfinance as yf
import pandas as pd
# Define the ticker symbol and date range
ticker_symbol = “BTC-USD”
start_date = “2020-01-01”
end_date = “2023-01-01”
# Download historical data using yfinance
data = yf.download(ticker_symbol, start=start_date, end=end_date)
# Create a Pandas DataFrame
df = pd.DataFrame(data)
# Create a Pandas Excel writer object
excel_writer = pd.ExcelWriter(‘bitcoin_historical_data.xlsx’, engine=’openpyxl’)
# Write the DataFrame to an Excel sheet
df.to_excel(excel_writer, sheet_name=’Bitcoin Historical Data’)
# Save the Excel file
excel_writer.save()
print(“Data has been saved to bitcoin_historical_data.xlsx”)
# Make sure you have the required libraries installed and adjust the “start_date” and “end_date” variables to the desired date range for the historical data you want to download.
The code above allows you to download the data from Yahoo! Finance.
R code
The R program below written by Shengyu ZHENG allows you to download the data from Yahoo! Finance website and to compute summary statistics and risk measures about the Bitcoin.

Data file
The R program that you can download above allows you to download the data for the Bitcoin from the Yahoo! Finance website. The database starts on September 17, 2014.
Table 3 below represents the top of the data file for the Bitcoin downloaded from the Yahoo! Finance website with the R program.
Table 3. Top of the data file for the Bitcoin.
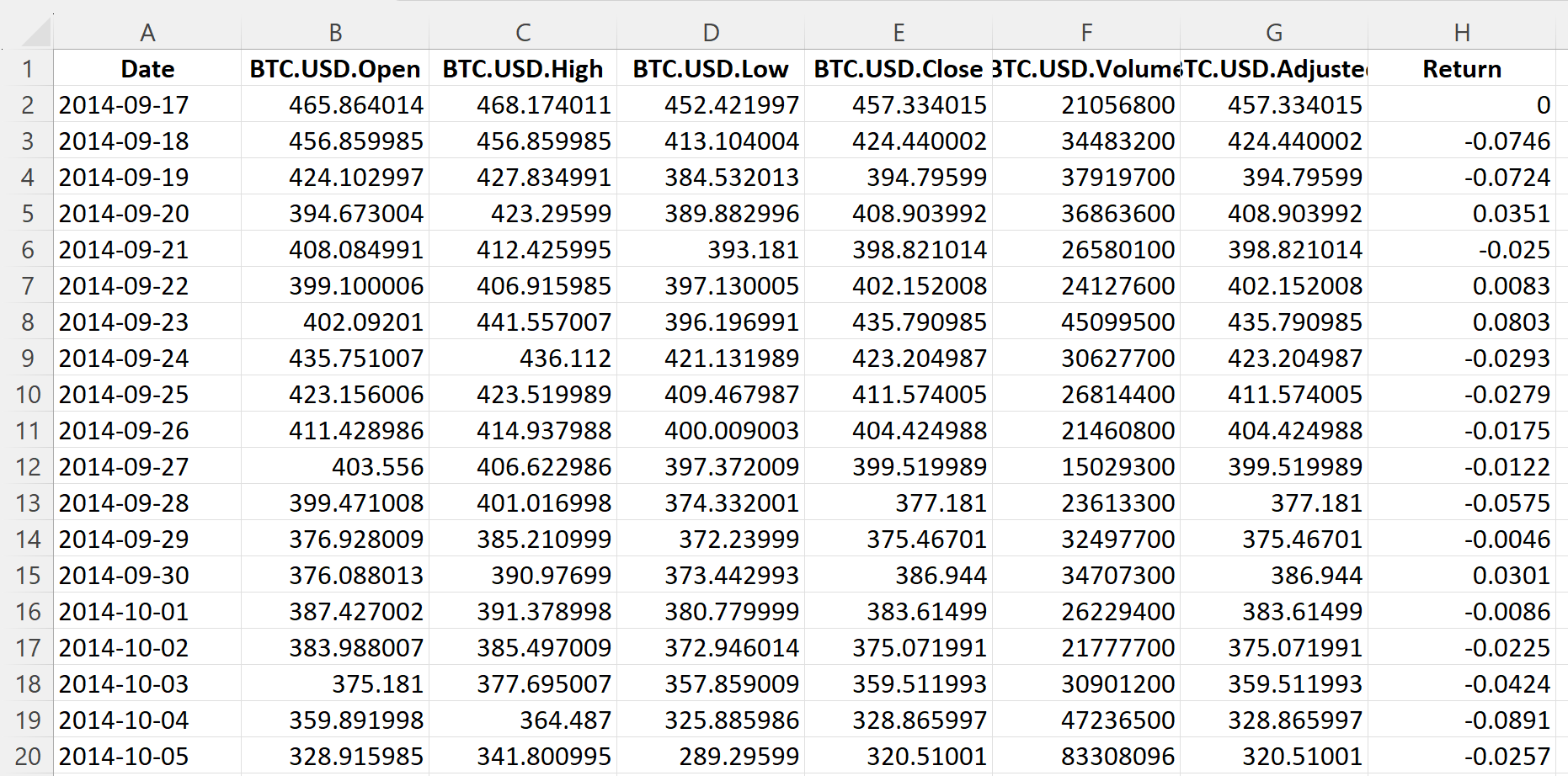
Source: computation by the author (data: Yahoo! Finance website).
Evolution of the Bitcoin
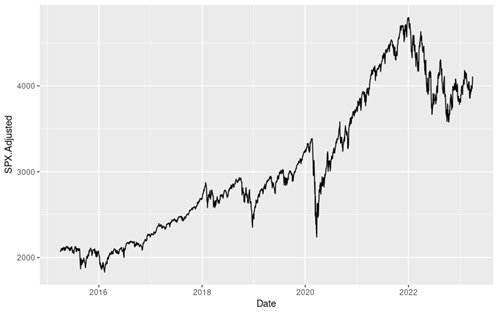
Figure 6 below gives the evolution of the Bitcoin from September 17, 2014 to December 31, 2022 on a daily basis.
Figure 6. Evolution of the Bitcoin.
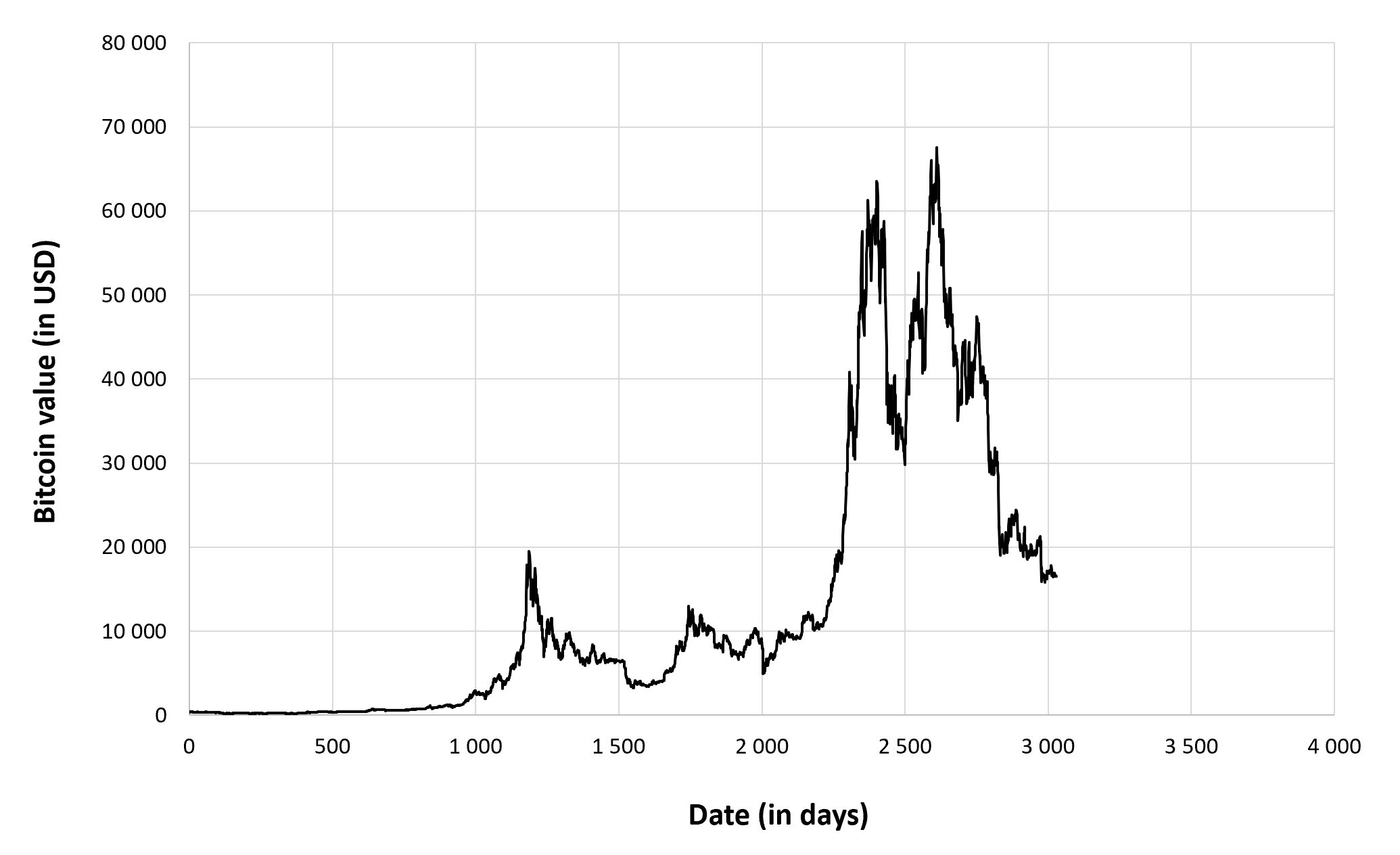
Source: computation by the author (data: Yahoo! Finance website).
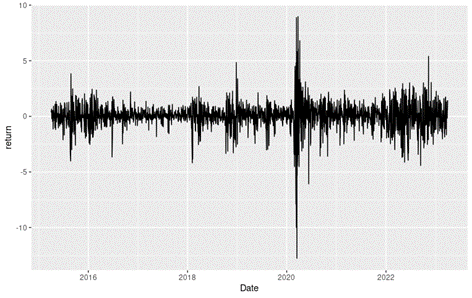
Figure 7 below gives the evolution of the Bitcoin returns from September 17, 2014 to December 31, 2022 on a daily basis.
Figure 7. Evolution of the Bitcoin returns.
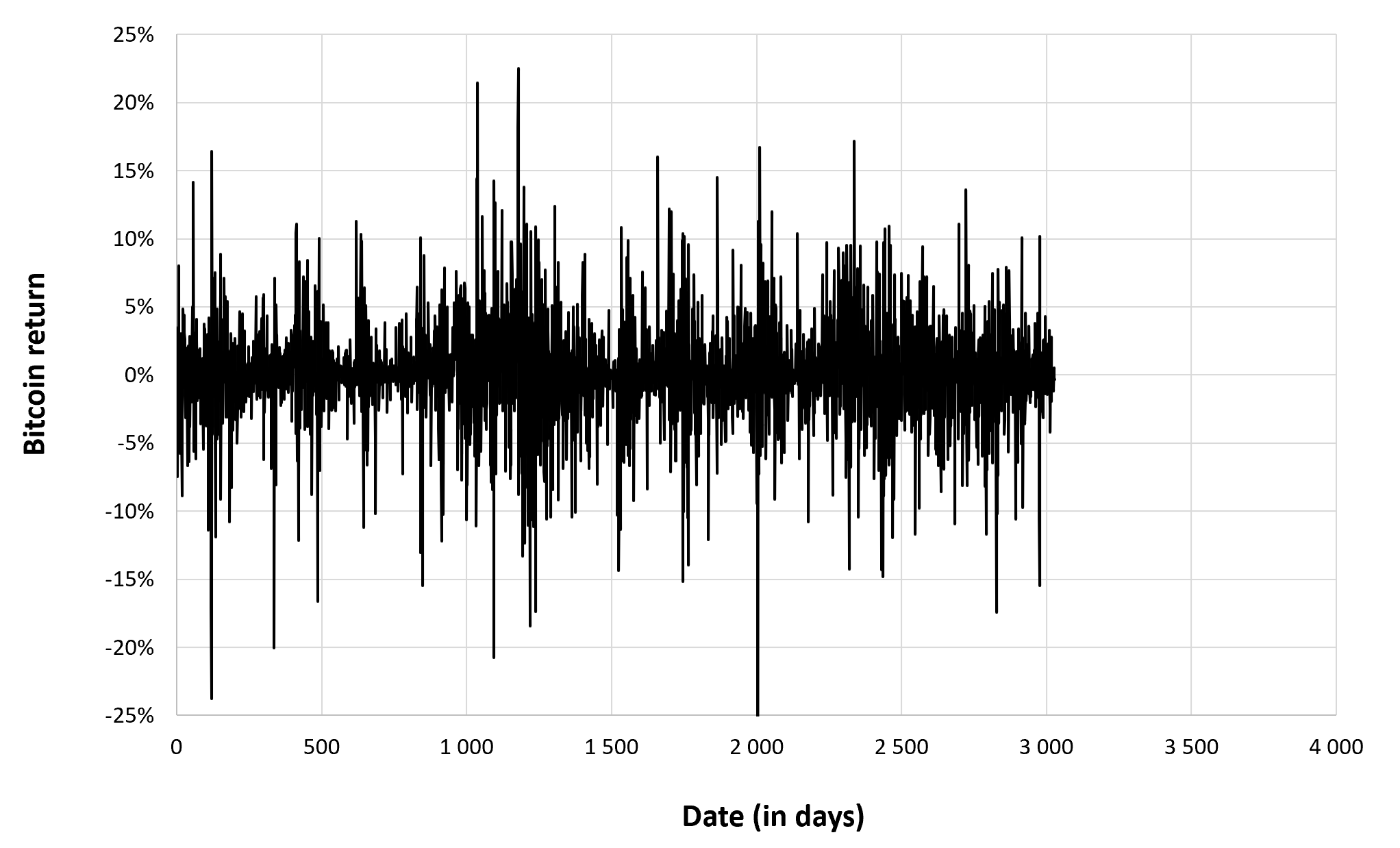
Source: computation by the author (data: Yahoo! Finance website).
Summary statistics for the Bitcoin
The R program that you can download above also allows you to compute summary statistics about the returns of the Bitcoin.
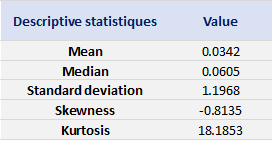
Table 4 below presents the following summary statistics estimated for the Bitcoin:
- The mean
- The standard deviation (the squared root of the variance)
- The skewness
- The kurtosis.
The mean, the standard deviation / variance, the skewness, and the kurtosis refer to the first, second, third and fourth moments of statistical distribution of returns respectively.
Table 4. Summary statistics for the Bitcoin.
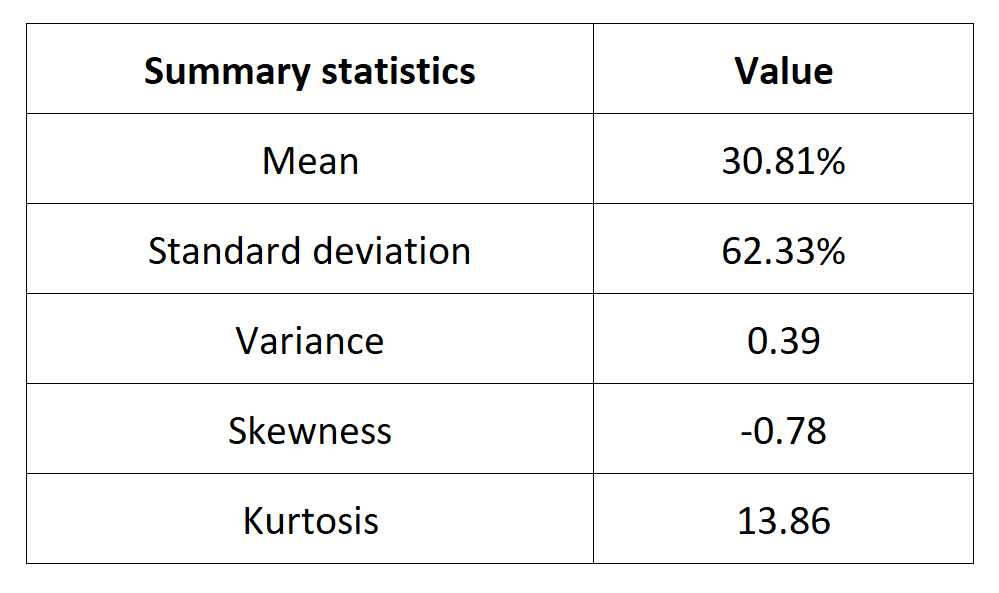
Source: computation by the author (data: Yahoo! Finance website).
Statistical distribution of the Bitcoin returns
Historical distribution
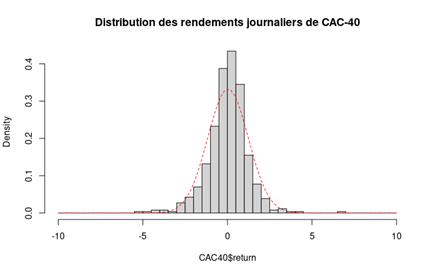
Figure 8 represents the historical distribution of the Bitcoin daily returns for the period from September 17, 2014 to December 31, 2022.
Figure 8. Historical distribution of the Bitcoin returns.
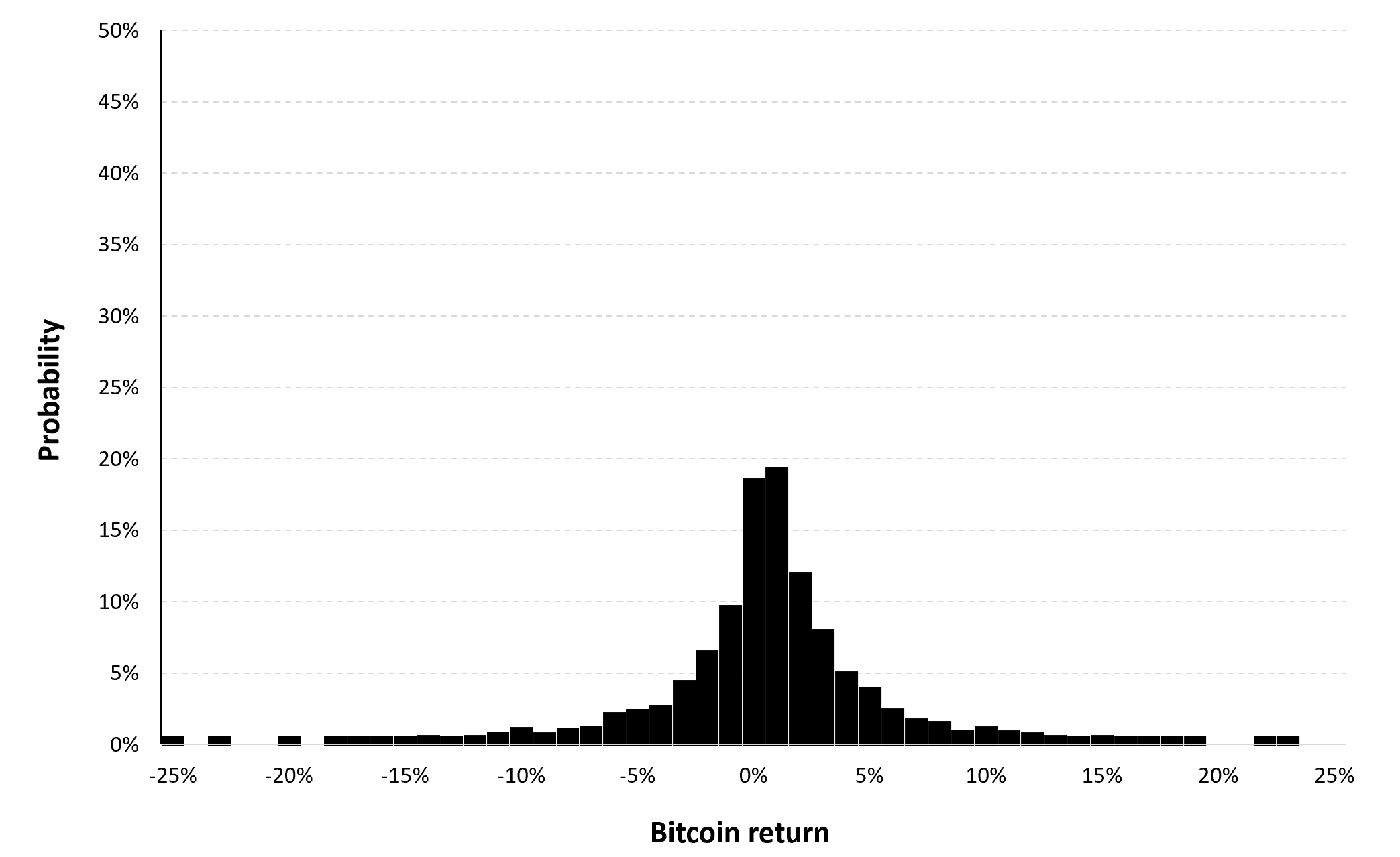
Source: computation by the author (data: Yahoo! Finance website).
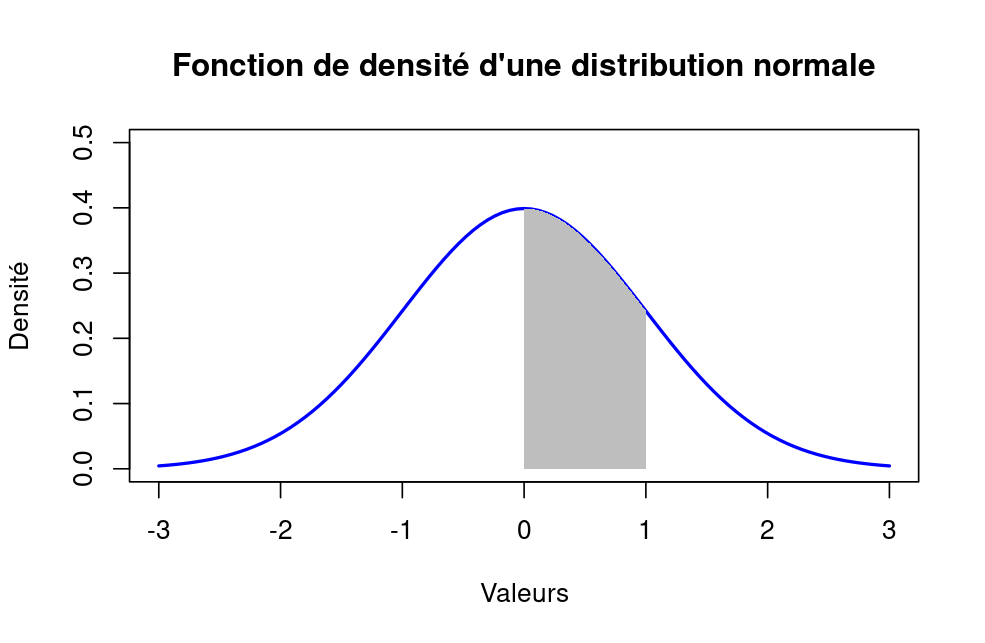
Gaussian distribution
The Gaussian distribution (also called the normal distribution) is a parametric distribution with two parameters: the mean and the standard deviation of returns. We estimated these two parameters over the period from September 17, 2014 to December 31, 2022. The annualized mean of daily returns is equal to 30.81% and the annualized standard deviation of daily returns is equal to 62.33%.
Figure 9 below represents the Gaussian distribution of the Bitcoin daily returns with parameters estimated over the period from September 17, 2014 to December 31, 2022.
Figure 9. Gaussian distribution of the Bitcoin returns.
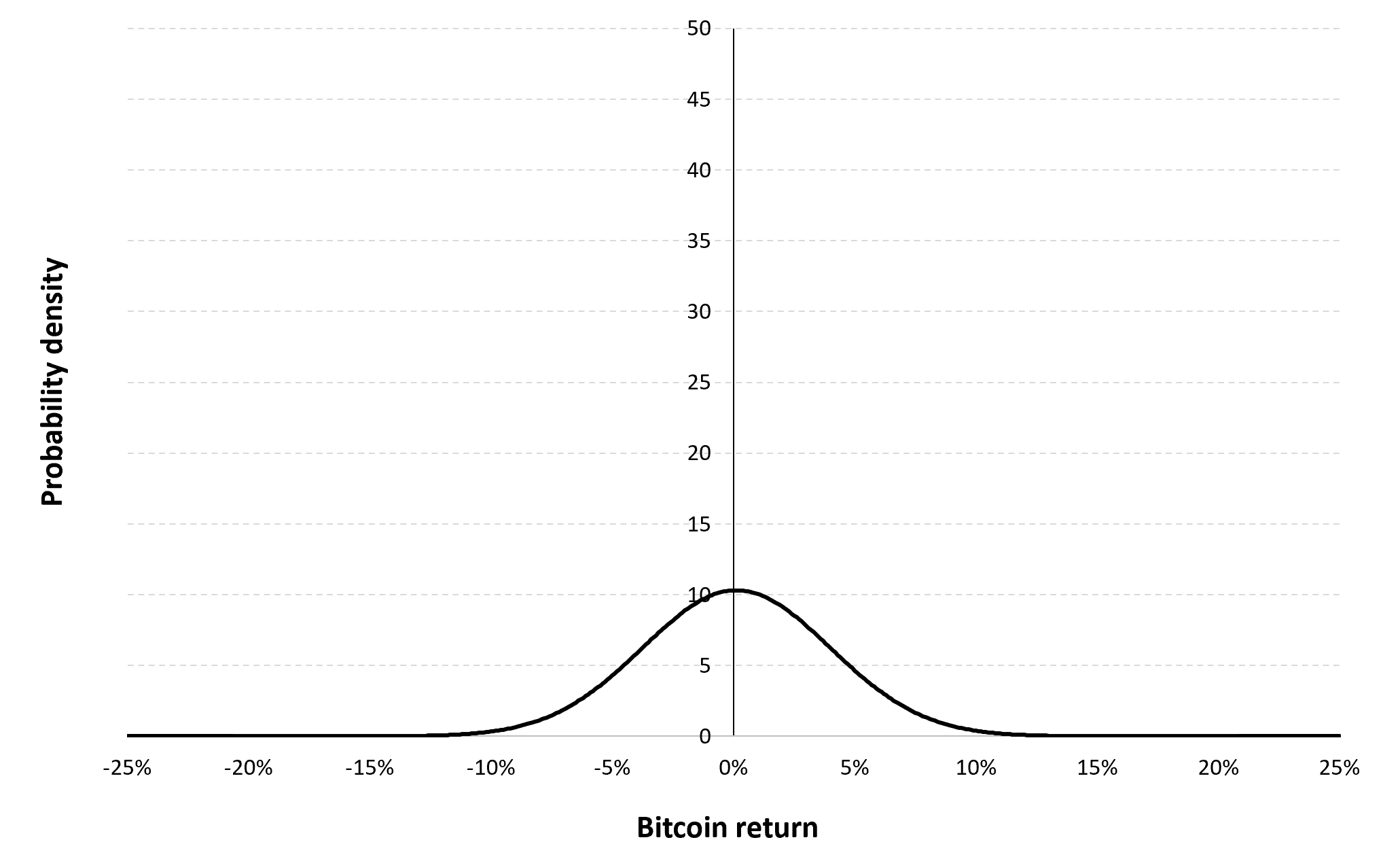
Source: computation by the author (data: Yahoo! Finance website).
Risk measures of the Bitcoin returns
The R program that you can download above also allows you to compute risk measures about the returns of the Bitcoin.
Table 5 below presents the following risk measures estimated for the Bitcoin:
- The long-term volatility (the unconditional standard deviation estimated over the entire period)
- The short-term volatility (the standard deviation estimated over the last three months)
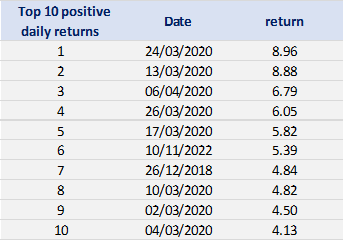
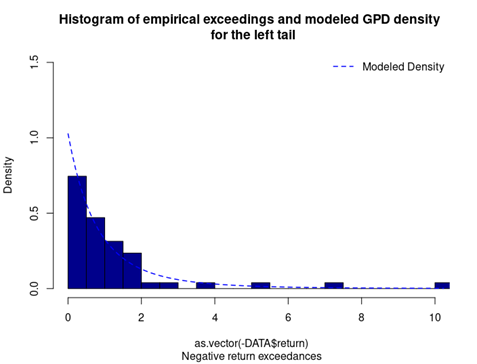
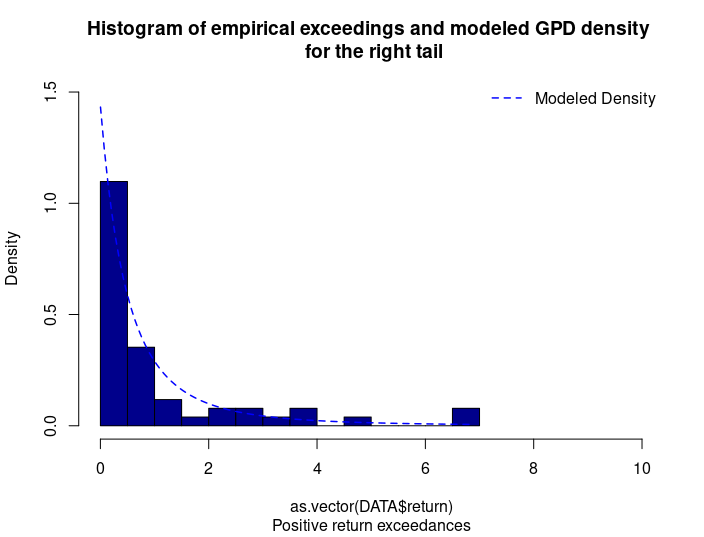
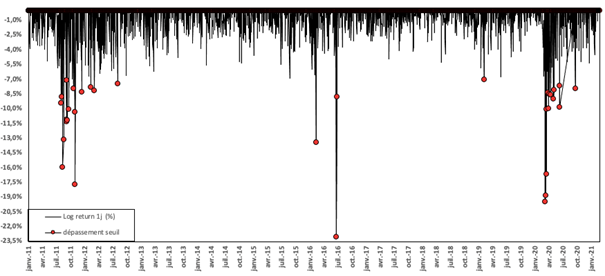
- The Value at Risk (VaR) for the left tail (the 5% quantile of the historical distribution)
- The Value at Risk (VaR) for the right tail (the 95% quantile of the historical distribution)
- The Expected Shortfall (ES) for the left tail (the average loss over the 5% quantile of the historical distribution)
- The Expected Shortfall (ES) for the right tail (the average loss over the 95% quantile of the historical distribution)
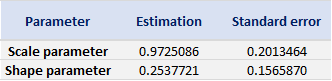
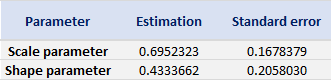
- The Stress Value (SV) for the left tail (the 1% quantile of the tail distribution estimated with a Generalized Pareto distribution)
- The Stress Value (SV) for the right tail (the 99% quantile of the tail distribution estimated with a Generalized Pareto distribution)
Table 5. Risk measures for the Bitcoin.
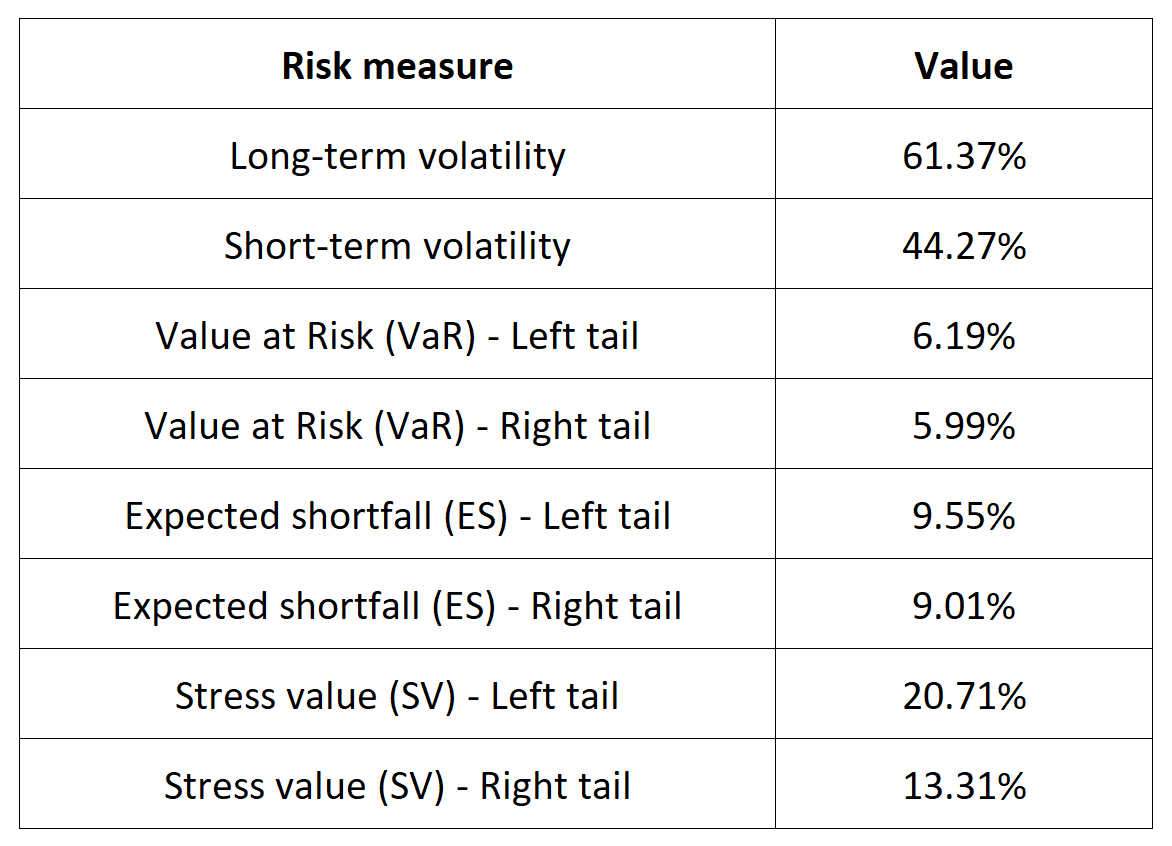
Source: computation by the author (data: Yahoo! Finance website).
The volatility is a global measure of risk as it considers all the returns. The Value at Risk (VaR), Expected Shortfall (ES) and Stress Value (SV) are local measures of risk as they focus on the tails of the distribution. The study of the left tail is relevant for an investor holding a long position in the Bitcoin while the study of the right tail is relevant for an investor holding a short position in the Bitcoin.
Why should I be interested in this post?
Students would be keenly interested in this article discussing Bitcoin’s history and trends due to its profound influence on the financial landscape. Bitcoin, as a novel and dynamic asset class, presents a unique opportunity for students to explore the evolving world of finance. By delving into Bitcoin’s past, understanding its market trends, and assessing its impact on global economies, students can equip themselves with the knowledge and skills needed to navigate a financial landscape that is increasingly intertwined with cryptocurrencies and blockchain technology. Moreover, this knowledge can enhance their career prospects in an industry undergoing significant transformation and innovation.
Related posts on the SimTrade blog
About cryptocurrencies
▶ Snehasish CHINARA How to get crypto data
▶ Alexandre VERLET Cryptocurrencies
▶ Youssef EL QAMCAOUI Decentralised Financing
▶ Hugo MEYER The regulation of cryptocurrencies: what are we talking about?
About statistics
▶ Shengyu ZHENG Moments de la distribution
▶ Shengyu ZHENG Mesures de risques
▶ Jayati WALIA Returns
Useful resources
Academic research about risk
Longin F. (2000) From VaR to stress testing: the extreme value approach Journal of Banking and Finance, N°24, pp 1097-1130.
Longin F. (2016) Extreme events in finance: a handbook of extreme value theory and its applications Wiley Editions.
Data
Yahoo! Finance Historical data for Bitcoin
CoinMarketCap Historical data for Bitcoin
About the author
The article was written in September 2023 by Snehasish CHINARA (ESSEC Business School, Grande Ecole Program – Master in Management, 2022-2024).