In this article, Micha FISHER (University of Mannheim, MSc. Management, 2021-2023) explains the concept of Tracking Error in the context of exchange traded funds (ETF).
This article will offer a short introduction to the concept of exchange-traded funds, will then describe several reasons for the existence of tracking errors and finish with a concise example on how tracking error can be calculated.
Exchange-traded funds
An exchange-traded fund is conceptionally very close to classical mutual funds, with the key difference being, that ETFs are traded on a stock exchange during the trading day. Most ETFs are so-called index funds and thus they try to replicate an existing index like the S&P 500 or the CAC 40. This sort of passive investing is aimed at following or tracking the underlying index as closely as possible. However, actively managed ETFs with the aim of outperforming the market do exist as well and typically come with higher management fees. There are several types of ETFs covering equity index funds, commodities or currencies with classical equity index funds being the most prominent.
The total volume of global ETF portfolios has increased substantially over the last two decades. At the beginning of the century total asset volume was in the low triple digit billions measured in USD. According to research by the Wall Street Journal total assets in ETF investments surpassed nine trillion USD in 2021.
The continuing attractiveness of exchange-traded index funds can be explained with the very low management fees, the clarity of the product objective, and the high liquidity of the investment vehicle. However, although especially the market leaders like BlackRock, the Vanguard Group or State Street offer products that come extremely close to mirroring their underlying index, exchange-traded funds do not perfectly track the evolution of the underlying index. This phenomenon is known as tracking error and will be discussed in detail below.
Theoretical measure of the Tracking Error
Simply speaking, the tracking error of an ETF is the difference in the returns of the underlying index (I for index) and the returns of the ETF itself (E for ETF). For a specific period, it is computed by taking the standard deviation of the differences between the two time-series.
![]()
Theoretically, it is possible to fully replicate an index in a portfolio and thus reach a tracking error of zero. However, there are several reasons why this is not achievable in practice.
Origins of the Tracking Error
The most important and obvious reason is that the Net Asset Value (NAV) of index funds is necessarily lower than the NAV of its underlying index. An index itself has no liabilities, as it is strictly speaking an instrument of measurement. On the other hand, even a passively managed index fund comes with expenses to pay for infrastructure, personnel, and marketing. These liabilities decrease the Net Asset Value of the fund. In general, a higher tracking error could indicate that the fund is not working efficiently compared to products of competitors with the same underlying index.
Another origin of tracking error can be found in specific sector ETFs and more niche markets with not enough liquidity. When the trading volume of a stock is very low, buying / selling the stock would increase / decrease the price (price impact). In this case an ETF could buy more liquid stocks with the aim to mirror the value development of the illiquid stock, which in turn could lead to a higher tracking error.
Another source of tracking error that occurs more severely in dividend-focused ETFs is the so-called cash drag. High dividend payments that are not instantly reinvested drag down the fund performance in contrast to the underlying index.
Of course, transaction fees of the marketplaces can reduce the fund performance as well. This is especially true if large rebalancing efforts are necessary due to a change of the index composition.
Lastly, there are also ways to reduce the effects described above. Funds can engage in security lending to earn additional money. In this case, the fund lends individual assets within the portfolio to other investors (mostly short sellers) for an agreed period in return for lending fees and possible interest. It should be noted, that while this might reduce tracking error, it also exposes the fund to additional counterparty risk.
Tracking Error: An Example
The sheet posted below shows a simple example of how the tracking error can be computed. To not include hundreds of individual shares, the example transformed the top ten positions within the Nasdaq-100 index into an artificial “Nasdaq-10” index. Although the data for the 23rd of September is accurate, the future data is of course randomly simulated.
By using the individual weights of the index components and their corresponding weights, the index returns for the next three months can be computed.
Figure 1: Three-months simulation of “Nasdaq-10” index.
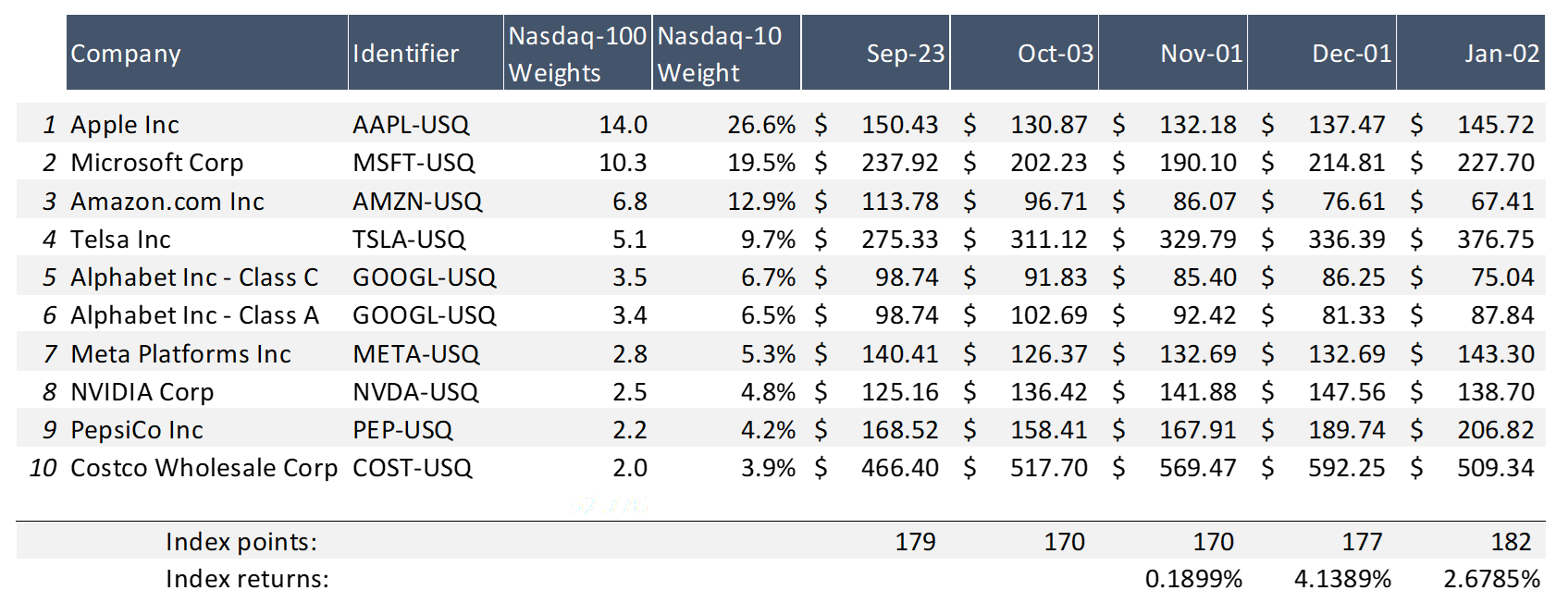
Source: computation by the author.
At this point our made-up ETF is introduced with an initial investment of 100 million USD. This ETF fully replicates the Nasdaq-10 index by holding shares in the same proportion as the index. In this example only the management and marketing fees are incorporated. Security lending, index changes and transaction fees and dividends are omitted. Also, all the portfolio shares are highly liquid and allow for full replication. The fund works with small expenses for personnel of only ten thousand USD per month. Additionally, once per quarter, a marketing campaign costs additionally fifty thousand USD.
Figure 2: Computation of ETF return and tracking error.
![]()
Source: computation by the author.
Calculating the net asset value (NAV) gives us the monthly returns of the fund which in turn allows us to calculate the three-month standard deviation of the tracking difference. Additionally, the Total Expense Ratio can be calculated as the percentage of expenses per year divided by the total asset value of the fund.
This example gives us a Total Expense Ratio of nearly 0.3 percent per annum which is within the competitive area of real passive funds. Vanguard is able to replicate the FTSE All-World index with 0.2 percent. However, the calculated tracking error is obviously smaller than most real tracking errors with only 0.0002, as only management fees were considered. Exemplary, Vanguards FTSE All-World ETF had an historical tracking error of 0.042 in 2021, due to the reasons mentioned in the section above.
Excel file for computing the tracking error of an ETF
You can also download below the Excel file for the computation of the tracking error of an ETF.

Why should I be interested in this post?
ETFs in all forms are one of the major developments in the area of portfolio management over the last two decades. They are also a very interesting option for private investments.
Although they are conceptually very simple it is important to understand the finer metrics that vary between different service providers as even small differences can have a large impact over a longer investment period.
Related posts on the SimTrade blog
▶ Youssef LOURAOUI ETFs in a changing asset management industry
▶ Youssef LOURAOUI Passive Investing
▶ Youssef LOURAOUI Markowitz Modern Portfolio Theory
Useful resources
Academic articles
Roll R. (1992) A Mean/Variance Analysis of Tracking Error, The Journal of Portfolio Management, 18 (4) 13-22.
Business
ET Money What is Tracking Error in Index Funds and How it Impacts Investors?
About the author
The article was written in November 2022 by Micha FISHER (University of Mannheim, MSc. Management, 2021-2023).